
Nachdem im ersten Teil der Salesforce Data Cloud Serie die Entstehung und Relevanz der Data Cloud erläutert wurde, und Teil zwei sich ihren zentralen Konzepten und Datenmodell widmete, betrachtet dieser dritte Teil nun die technische Architektur der Data Cloud und schließt die Serie.
Data Cloud Architektur
Salesforce setzt bei der Data Cloud auf eine hochmoderne Datenarchitektur, die nicht nur effizient ist, sondern auch die Flexibilität eines Data Lakes mit den Vorteilen eines Data Warehouses vereint – die sogenannte „Lakehouse“-Architektur.
Von der Datenbank zum Lakehouse
Im Unterschied zu den herkömmlichen relationalen Datenbanken, die das Salesforce-Ökosystem seit Jahrzehnten prägen, verfolgt die Data Cloud einen Data Lake Ansatz zur Speicherung aller Daten. Ein Data Lake ist im Wesentlichen ein Dateisystem, das Dateien in unterschiedlichsten Formaten in einer hierarchischen Ordnerstruktur ablegen kann. Salesforce nutzt hier eine Kombination aus DynamoDB, um „heiße“ Daten – das heißt Daten, die besonders schnell verfügbar sein müssen – zu speichern, und einen Data Lake a la Amazon S3 für die langfristige Speicherung „kalter“ Daten.
Das Lakehouse – ein Warehouse im Data Lake
Die alternative zur Datenbank ergibt sich aber erst, sobald ein Data Lake ACID-kompatibel per SQL abfragbar und somit zum flexiblen und robusteren Transactional Data Lake wird.
SQL-Abfragen auf Data Lakes sind zwar nicht neu – Facebook führte diese Funktionalität bereits 2010 mit Apache Hive im Hadoop-Ökosystem ein und verlieh den Daten des Hadoop File Systems damit einen SQL Intellekt – doch AWS hat diese Funktionalität weiterentwickelt und bietet mit S3 und dem Glue Data Catalog eine proprietäre Lösung, die SQL-basierte Abfragen auf S3-Daten ermöglicht.
Vor diesem historischen Hintergrund nutzt Salesforce die grundlegende Architektur des Data Lakes mit Metadatenkatalog und baut auf Vorgängertechnologien auf, um mit den Leistungs- und Skalierungsbeschränkungen herkömmlicher relationaler Datenbanken zu brechen.
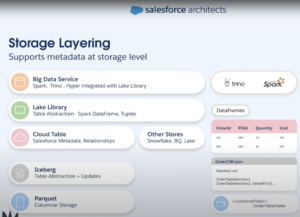
Der Schlüssel dazu liegt allerdings in dem Teil des Technologie-Stacks begründet, der auf dem Metadatenkatalog aufsetzt. Die Data Cloud macht sich den hochmodernen Open Source Datenarchitekturstack „Trino on Ice“ zu Nutze, der Apache Trino mit Apache Iceberg kombiniert. Beide dieser Tools sind zentrale Elemente der Data Cloud Architektur und werden nun kurz beleuchtet:
Seit der Veröffentlichung durch Netflix 2017 ist Apache Iceberg der Platzhirsch am Markt der Transactional Data Lake Frameworks. Dem namensgebenden metaphorischen Eisberg gleich will Apache Iceberg die Dateien und Ordnerstrukturen des Data Lake „unter der Oberfläche“ hinter einer schmalen Schnittstelle kapseln und für Nutzer transparent machen. Dafür bietet Iceberg Funktionalität, die große, komplexe Datenmengen und ihre Verarbeitung handhabbar macht. Das Framework kümmert dazu bspw. vollautomatisch um die Optimierung von Dateigrößen durch automatisches Rewriting und fasst somit fragmentierte Dateien, die aus kontinuierlichen Datenströmen (z.B. aus Apache Kafka) ensttehen, zu performanten Dateien zusammen. Iceberg verwaltet weiterhin gleichzeitige Zugriffe auf Daten und stellt so auch bei der Manipulation großer Datenmengen die Einhaltung der ACID-Kriterien sicher. Zusätzlich partitioniert es den Data Lake automatisch zur Performanceoptimierung von Abfragen und bietet mit Snapshots auch günstige Möglichkeiten für Rollbacks.
Apache Trino (früher als Presto bekannt) ist eine massiv-parallele SQL Query Engine, die durch ihre hohe Performance und Parallelisierung von Abfragen häufig das Mittel der Wahl für Big-Data Anwendungen darstellt. So ist Trino bspw. auch als die Engine hinter Amazon Athena zur Abfrage des Glue Data Catalog bekannt. Trino schreibt sich auf die Fahne, Abfragen heterogener Datenquellen „ludicrously fast“ (aka extrem schnell und effizient) zu machen.
Durch die Kombination von Apache Iceberg mit Trino können Daten effizient verwaltet, bereitgestellt und verarbeitet werden – ideal für Analysen und schnelle Abfragen in Echtzeit. In der Data Cloud arbeitet Trino daher eng mit Iceberg zusammen, um eine nahtlose und performante Abfrageschicht zu schaffen.
Gemeinsam realisieren diese Technologien eine Lakehouse-Architektur, die Daten performant und organisiert für Analysen und Automatisierung zur Verfügung stellt, ohne diese erst in ein klassisches Data Warehouse replizieren zu müssen. Daten werden stattdessen in Zero-Copy-Manier durch die dünne, direkt auf dem Data Lake sitzende Abfrageschicht zur Verfügung gestellt. Diese Struktur und die eingesetzten Technologien erlauben die effiziente Verarbeitung enormer Datenmengen und verleihen der Data Cloud eine für datenintensive Anwendungen und Echtzeitanalysen optimierte Lakehouse Architektur.
Lakehouse Architektur für alle
Ein entscheidender Vorteil der Data Cloud liegt in ihrer Benutzerfreundlichkeit: Während Anbieter wie AWS zwar die nötigen Bausteine für eine ähnliche Architektur bereitstellen, ist die Implementierung und Integration oft komplex und setzt tiefgehende Coding-Skills voraus – zum Beispiel für Spark-Implementierungen in Glue Jobs. Salesforce hingegen kapselt den gesamten Technologiestack hinter einer intuitiven Benutzeroberfläche, die es auch Anwendern ohne spezifische Big-Data-Kenntnisse ermöglicht, die Lakehouse-Architektur zu nutzen. Diese Benutzerfreundlichkeit macht die Data Cloud zur ersten Wahl für Unternehmen, die sowohl auf fortschrittliche Datenverarbeitung als auch auf einfache Handhabung Wert legen.
Ein weiteres Plus der Salesforce Data Cloud ist ihre Offenheit und Kompatibilität mit gängigen Technologien und Formaten. Salesforce setzt hier auf bewährte Open-Source-Standards wie Parquet für die Datenspeicherung und Trino sowie Iceberg für die Datenverarbeitung und -verwaltung. Dadurch bleibt die Data Cloud nicht nur flexibel und skalierbar, sondern öffnet sich auch für die direkte Zero-Copy Integration mit externen Systemen wie Snowflake. Unternehmen können so auf die Daten der Data Cloud zugreifen, ohne dass physische Datenverschiebungen erforderlich sind, was sowohl die Performance als auch die Effizienz steigert.
Fazit
Für Architekten bedeutet die Beherrschung der Data Cloud-Architektur die Fähigkeit, modernste Datenlösungen bereitzustellen, Unternehmen dabei zu unterstützen, das volle Potenzial ihrer Daten auszuschöpfen und eine Grundlage für zukunftsfähige KI-Lösungen zu schaffen. Die Data Cloud vereint innovative Technologien mit einer intuitiven Bedienbarkeit für einen erheblichen Wettbewerbsvorteil. Salesforce hat mit der Data Cloud also eine Brücke zwischen den Welten von Data Lakes und Data Warehouses geschlagen und eine vollständig integrierte, benutzerfreundliche Lösung geschaffen, um flexibel mit den zukünftigen Herausforderungen der Datenverarbeitung mitzuwachsen.
- Sie interessieren sich für unsere Services rund um Salesforce Data Cloud? Besuchen Sie unsere Salesforce Themenseite!